I paid for Xfce
Yesterday I caved in and bought myself one of those cute little laptop devices: an Acer Aspire One.

Note that the giant machine on the left is my previously considered smallish 14.1″ laptop from Dell.
It comes with a Taiwanese distribution, Linpus Linux, based on Fedora 8. More specifically, it comes with the ‘Lite’ variant of the distribution which features Xfce as its desktop environment. Well, actually, it is part modified Xfce, part Easy(tm) interface created by Acer for this device (they call it xfdesktop2, a bit strange if you ask me).
Wow. A commercial offering available from a store for regular people, with software that I helped create. Awesome. Maybe I should have asked for a discount ;-)
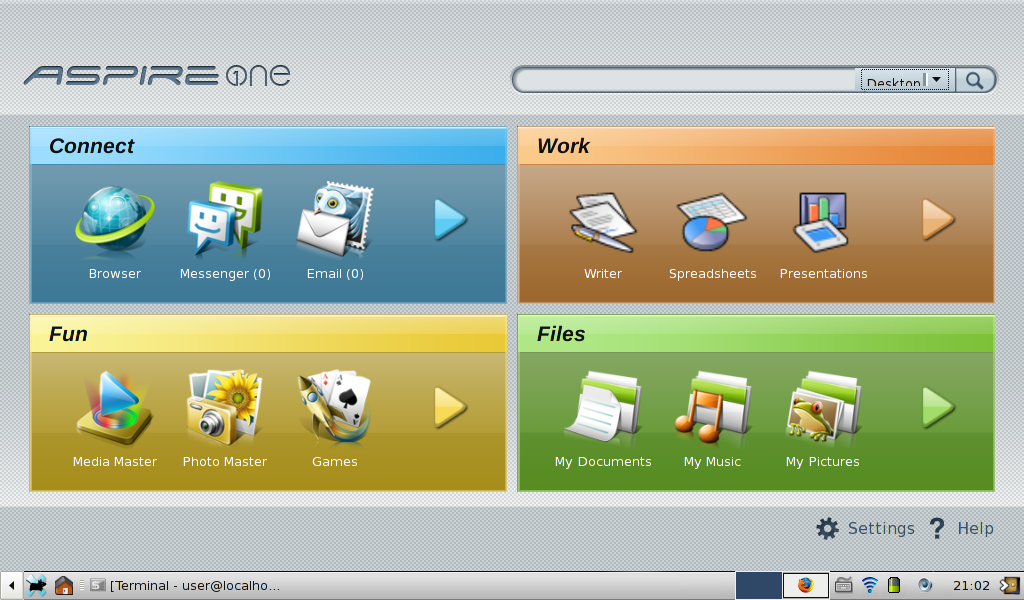
I’ve just started playing with it and I think they did a pretty good job. The interface is really easy, but can only access a few predefined applications. I have wanted to write such a full screen launcher/control center interface for a long time, but never got around to actually doing anything about it. It would be perfect for my parents, who have a very hard time working with their Windows XP.
They use a modified Thunar (My Disk://, Removable://, indication of disk usage in the side bar) that seems to work fairly well.
They don’t provide easy access to changing the configuration, since they disabled the right mouse menu on the panel. However Alt-F2 brings up xfrun as in a regular Xfce installation and Terminal is installed.
There’s xfce-setting-show to bring up our own settings dialog. It doesn’t fit on the screen (1024×600), but this is partly due to the very big icon they added for screen settings, making all buttons in the dialog much bigger than they need to be. I got rid of the XP window decorations and used the Xfce theme instead of RedHat’s Nodoko. Now that looks better!
xfce4-panel -a gives you the add item menu, where you can add for instance the xfdesktop menu. Also in edit mode some right-click menus do become available (not all). I’ve added a menu and a pager to get a bit more functionality.
Since it’s based on fedora you can use yum to install more software. I’ve just installed gimp to be able to create a decently sized picture for this post.
It has an 8GB SSD for storage and two card reader slots for possible extensions. The one thing where the SSD really shows its advantage is boot time. It boots in about 15 seconds, maybe a bit less (although some daemons are still being started in the background), very nice indeed.
Oh, and it weighs slightly less than 1 kg.
So, now I’ll go back to playing with this thing ;-)
update:
Screenshot
{kind=link}
Git Snapshot Versioning?
With our SVN repository, we version SVN snapshots using the SVN revision number – we tack “svn-r$REVISION” on the end of the normal version number. This works well, and it’s easy to tell if a given snapshot is newer or older than another one.
Git doesn’t have revision numbers. Commits are identified by SHA1 checksums. Since these are “random,” there’s no way to tell chronological order. How are other people doing git snapshot versioning? The best I’ve come up with is to parse git-log output to get the date and time of the last commit, and then do something like X.Y.Zgit-YYYYMMDD.HHMMSS… which is rather long and ugly. I guess it would be ok to use a 2-digit year here, though. And maybe drop the seconds bit, but I think it’s decently possible to have more than one commit in the same minute. But still… long and ugly.
Any other ideas? My requirements are simple: easy to tell based on just the version string if a snapshot is older or newer than another, must be able to automatically generate this tag, and must be able to identify the exact HEAD that the snapshot was made from.
Git Snapshot Versioning?
With our SVN repository, we version SVN snapshots using the SVN revision number -- we tack "svn-r$REVISION" on the end of the normal version number. This works well, and it's easy to tell if a given snapshot is newer or older than another one.
Git doesn't have revision numbers. Commits are identified by SHA1 checksums. Since these are "random," there's no way to tell chronological order. How are other people doing git snapshot versioning? The best I've come up with is to parse git-log output to get the date and time of the last commit, and then do something like X.Y.Zgit-YYYYMMDD.HHMMSS... which is rather long and ugly. I guess it would be ok to use a 2-digit year here, though. And maybe drop the seconds bit, but I think it's decently possible to have more than one commit in the same minute. But still... long and ugly.
Any other ideas? My requirements are simple: easy to tell based on just the version string if a snapshot is older or newer than another, must be able to automatically generate this tag, and must be able to identify the exact HEAD that the snapshot was made from.
More Firefox 3 SSL Junk
Lately I’ve noticed a flood of Firefox 3-related posts regarding the new SSL error handling on Planet GNOME. It’s a little funny, as I was writing about this myself a little under two months ago.
Chris Blizzard posts in favor of the new arrangement, and points to an interesting post by Johnathan Nightingale explaining Mozilla’s position. Yes, agreed, Jonathan’s post is a good read, but the salient point is that the new UI is just awful from an average non-technical user’s perspective.
The extra clicks and somewhat abnormal flow (e.g. the need to click a button in the dialog to fetch the certificate) make it harder for the user to understand how to successfully add the exception. You might say that some false positives (i.e., users who fail to access a site that they really actually do want to access) is better than a user succumbing to a MITM attack, but I’m not sure I’d agree.
Equally importantly, the error messages make no distinction between the potential severity of the various SSL errors. For example, I’d say a self-signed cert on a site that you’ve never visited before is fairly low-risk. But a self-signed cert on a site that used to have a trusted cert would be a huge red flag. Domain mismatches and expired certs would fall somewhere in between. It’s hard for the average user to make an informed decision on risk/severity if they were to encounter both of these situations because the error messages and dialogs look exactly the same.
Addressing Johnathan’s main point about self-signed certs and level of security: as a highly technical/advanced user, I personally can say that, in the vast majority of instances where I encounter a self-signed cert, I really do just care about the encryption, and I don’t particularly care about the identity verification of the site that a trusted cert could offer. Now, Firefox probably shouldn’t use me as an example as a target user that needs protection, but that’s a data point nonetheless. I don’t care for things like: Bugzilla installations, my blog, accounts at sites like identi.ca, Twitter, Slashdot (they don’t offer SSL at present, but if they did…), etc.
Pretty much the only time I do care are for financial institutions. And guess what? They’ve already decided that SSL as used for identity verification is useless! Most of them (I can only think of one that I use that hasn’t) have already implemented a “security image” system wherein I pick a random image that gets shown to me every time I log in. If a site claiming to be the site I want shows me an image I don’t recognise, I’ll know that the site is a fraud. Is it perfect? Probably not. But it’s orders of magnitude better then what SSL error dialogs offer.
And I guess that’s really it: as much as I hate the phrase, I really think that the SSL error dialogs are “a solution in search of a problem.” In the cases where I care about site spoofing, the sites themselves have already implemented a better solution. In the cases where I don’t care, well… I don’t care.
More Firefox 3 SSL Junk
Lately I've noticed a flood of Firefox 3-related posts regarding the new SSL error handling on Planet GNOME. It's a little funny, as I was writing about this myself a little under two months ago.
Chris Blizzard posts in favor of the new arrangement, and points to an interesting post by Johnathan Nightingale explaining Mozilla's position. Yes, agreed, Jonathan's post is a good read, but the salient point is that the new UI is just awful from an average non-technical user's perspective.
The extra clicks and somewhat abnormal flow (e.g. the need to click a button in the dialog to fetch the certificate) make it harder for the user to understand how to successfully add the exception. You might say that some false positives (i.e., users who fail to access a site that they really actually do want to access) is better than a user succumbing to a MITM attack, but I'm not sure I'd agree.
Equally importantly, the error messages make no distinction between the potential severity of the various SSL errors. For example, I'd say a self-signed cert on a site that you've never visited before is fairly low-risk. But a self-signed cert on a site that used to have a trusted cert would be a huge red flag. Domain mismatches and expired certs would fall somewhere in between. It's hard for the average user to make an informed decision on risk/severity if they were to encounter both of these situations because the error messages and dialogs look exactly the same.
Addressing Johnathan's main point about self-signed certs and level of security: as a highly technical/advanced user, I personally can say that, in the vast majority of instances where I encounter a self-signed cert, I really do just care about the encryption, and I don't particularly care about the identity verification of the site that a trusted cert could offer. Now, Firefox probably shouldn't use me as an example as a target user that needs protection, but that's a data point nonetheless. I don't care for things like: Bugzilla installations, my blog, accounts at sites like identi.ca, Twitter, Slashdot (they don't offer SSL at present, but if they did...), etc.
Pretty much the only time I do care are for financial institutions. And guess what? They've already decided that SSL as used for identity verification is useless! Most of them (I can only think of one that I use that hasn't) have already implemented a "security image" system wherein I pick a random image that gets shown to me every time I log in. If a site claiming to be the site I want shows me an image I don't recognise, I'll know that the site is a fraud. Is it perfect? Probably not. But it's orders of magnitude better then what SSL error dialogs offer.
And I guess that's really it: as much as I hate the phrase, I really think that the SSL error dialogs are "a solution in search of a problem." In the cases where I care about site spoofing, the sites themselves have already implemented a better solution. In the cases where I don't care, well... I don't care.