Code Comments
I’m a bit of a minimalist when it comes to commenting my code. This is probably in some ways a bad thing; code that is completely obvious to me in its function may be difficult to understand for others, and I’m often not so great at realizing this on the first pass.
So that leads me to the purpose of code comments:
The purpose of commenting your code is to inform readers of that code what a section of nontrivial or non-obvious code does.
At least, this is my definition. Opinions differ, I’m sure. I might also add to that a clarification: “readers” in this case may include yourself. Code you wrote may even be incomprehensible to you if a decent amount of time has passed.
From this definition you can also infer something else, that I believe it’s unnecessary to comment obvious code. In fact, I’d argue that it’s harmful to comment obvious code, because you’re making it harder to follow, and you’re adding a barrier in front of the reader being easily able to distinguish between trivial and nontrivial code at a glance. You also increase the length of the code fragment, which may make it more difficult to read and understand in its entirety (if you can’t fit the entire fragment on one screen, you’ll have to scroll back and forth to see the entire thing).
However, too often – very often, it turns out – I see things like the following:
And one of my favorites:
(Yes, I actually have seen something very similar to that, though I don’t remember what the label text was.)
How do these comments actually add anything useful to the file? Every time I see one of these, a little part of me dies inside.
Now, the last one is just silly. Even someone who has never developed using the gtk+ UI toolkit can figure out what that line of code does without the comment. If you can’t, then a code comment there probably isn’t going to be enough to help you overall in any case.
The middle one is equally silly, though it’s understandable that someone
might not know that g_free() is the glib equivalent of free(). However,
consider your audience: is an extra line of code for a comment really
useful here?
The first one is not quite so easy for me to dismiss. It presupposes a few bits of knowledge:
- Understanding of what reference-counted memory management is.
- Familiarity with the “ref/unref” pair, as opposed to only being exposed to something like the OpenStep “retain/release” (or even the COM/XPCOM “AddRef/Release”) terminology.
- At least passing knowledge of what a GObject is.
Now, for code that makes heavy use of reference counting, I think presupposing #1 is not unreasonable. In this case, it doesn’t matter: the comment as presented will not help you if you don’t know what reference counting is.
Points #2 and #3 depend on your goals and potential audience. If you
think that a decent number of readers may not be familiar with the
“ref/unref” terminology, “take a reference” is probably enough to
generate an “oh, duh!” moment in the reader’s head. As for #3, unless
you intend your code to be able to act as a sort of GObject tutorial,
that is, something that people aspiring to learn GObject programming
might want to read, I think the comment there does not serve people
unfamiliar with GObject. Regardless, most GObject-using code will
probably be pretty confusing to someone who doesn’t know GObject, so
whether or not you should comment g_object_ref() is going to be the
least of your worries.
Now, I’m not going to claim that my code commenting is perfect… far from it. I could certainly stand to sprinkle comments a bit more liberally throughout my code. I tend to only comment public API (and then just a description of what the function does, not how it does it), and code fragments that are really nontrivial1 and potentially hard to understand.
But there has to be a happy medium somewhere. While too-infrequent commenting can certainly make code harder to understand, I’d argue that too-frequent commenting is worse. It’s sorta like “the boy who cried wolf” in the sense that comments draw my eyes to them as a way of saying, “pay attention! This bit here is important!” (or tricky, or whatever). Overuse of comments just makes me start skipping over all of them, useful or otherwise.
of comments. I generally prefer clear code over neat hacks, even if the neat hack represents a reduction in lines of code or a moderate increase in performance. If I write a section of code and then look at it again and see that it looks too complex, I’ll usually try to immediately rewrite it to be simpler.
-
It’s worth noting here that this point further reduces my volume ↩
Code Comments
I'm a bit of a minimalist when it comes to commenting my code. This is probably in some ways a bad thing; code that is completely obvious to me in its function may be difficult to understand for others, and I'm often not so great at realizing this on the first pass.
So that leads me to the purpose of code comments:
The purpose of commenting your code is to inform readers of that code what a section of nontrivial or non-obvious code does.
At least, this is my definition. Opinions differ, I'm sure. I might also add to that a clarification: "readers" in this case may include yourself. Code you wrote may even be incomprehensible to you if a decent amount of time has passed.
From this definition you can also infer something else, that I believe it's unnecessary to comment obvious code. In fact, I'd argue that it's harmful to comment obvious code, because you're making it harder to follow, and you're adding a barrier in front of the reader being easily able to distinguish between trivial and nontrivial code at a glance. You also increase the length of the code fragment, which may make it more difficult to read and understand in its entirety (if you can't fit the entire fragment on one screen, you'll have to scroll back and forth to see the entire thing).
However, too often -- very often, it turns out -- I see things like the following:
``/* take a reference */ g_object_ref(object);````/* free string */ g_free(str);``
And one of my favorites:
``/* set the label text to "Time Left:" */ gtk_label_set_text(GTK_LABEL(label), "Time Left:");``
(Yes, I actually have seen something very similar to that, though I don't remember what the label text was.)
How do these comments actually add anything useful to the file? Every time I see one of these, a little part of me dies inside.
Now, the last one is just silly. Even someone who has never developed using the gtk+ UI toolkit can figure out what that line of code does without the comment. If you can't, then a code comment there probably isn't going to be enough to help you overall in any case.
The middle one is equally silly, though it's understandable that someone might not know that g_free() is the glib equivalent of free(). However, consider your audience: is an extra line of code for a comment really useful here?
The first one is not quite so easy for me to dismiss. It presupposes a few bits of knowledge:
Understanding of what reference-counted memory management is.
Familiarity with the "ref/unref" pair, as opposed to only being exposed to something like the OpenStep "retain/release" (or even the COM/XPCOM "AddRef/Release") terminology
At least passing knowledge of what a GObject is
Now, for code that makes heavy use of reference counting, I think presupposing #1 is not unreasonable. In this case, it doesn't matter: the comment as presented will not help you if you don't know what reference counting is.
Points #2 and #3 depend on your goals and potential audience. If you think that a decent number of readers may not be familiar with the "ref/unref" terminology, "take a reference" is probably enough to generate an "oh, duh!" moment in the reader's head. As for #3, unless you intend your code to be able to act as a sort of GObject tutorial, that is, something that people aspiring to learn GObject programming might want to read, I think the comment there does not serve people unfamiliar with GObject. Regardless, most GObject-using code will probably be pretty confusing to someone who doesn't know GObject, so whether or not you should comment g_object_ref() is going to be the least of your worries.
Now, I'm not going to claim that my code commenting is perfect... far from it. I could certainly stand to sprinkle comments a bit more liberally throughout my code. I tend to only comment public API (and then just a description of what the function does, not how it does it), and code fragments that are really nontrivial[1] and potentially hard to understand.
But there has to be a happy medium somewhere. While too-infrequent commenting can certainly make code harder to understand, I'd argue that too-frequent commenting is worse. It's sorta like "the boy who cried wolf" in the sense that comments draw my eyes to them as a way of saying, "pay attention! This bit here is important!" (or tricky, or whatever). Overuse of comments just makes me start skipping over all of them, useful or otherwise.
<>[1] It's worth noting here that this point further reduces my volume of comments. I generally prefer clear code over neat hacks, even if the neat hack represents a reduction in lines of code or a moderate increase in performance. If I write a section of code and then look at it again and see that it looks too complex, I'll usually try to immediately rewrite it to be simpler.
Code Comments
I’m a bit of a minimalist when it comes to commenting my code. This is probably in some ways a bad thing; code that is completely obvious to me in its function may be difficult to understand for others, and I’m often not so great at realizing this on the first pass.
So that leads me to the purpose of code comments:
The purpose of commenting your code is to inform readers of that code what a section of nontrivial or non-obvious code does.
At least, this is my definition. Opinions differ, I’m sure. I might also add to that a clarification: “readers” in this case may include yourself. Code you wrote may even be incomprehensible to you if a decent amount of time has passed.
From this definition you can also infer something else, that I believe it’s unnecessary to comment obvious code. In fact, I’d argue that it’s harmful to comment obvious code, because you’re making it harder to follow, and you’re adding a barrier in front of the reader being easily able to distinguish between trivial and nontrivial code at a glance. You also increase the length of the code fragment, which may make it more difficult to read and understand in its entirety (if you can’t fit the entire fragment on one screen, you’ll have to scroll back and forth to see the entire thing).
However, too often — very often, it turns out — I see things like the following:
/* take a reference */ g_object_ref(object);
/* free string */ g_free(str);
And one of my favorites:
/* set the label text to "Time Left:" */ gtk_label_set_text(GTK_LABEL(label), "Time Left:");
(Yes, I actually have seen something very similar to that, though I don’t remember what the label text was.)
How do these comments actually add anything useful to the file? Every time I see one of these, a little part of me dies inside.
Now, the last one is just silly. Even someone who has never developed using the gtk+ UI toolkit can figure out what that line of code does without the comment. If you can’t, then a code comment there probably isn’t going to be enough to help you overall in any case.
The middle one is equally silly, though it’s understandable that someone might not know that g_free() is the glib equivalent of free(). However, consider your audience: is an extra line of code for a comment really useful here?
The first one is not quite so easy for me to dismiss. It presupposes a few bits of knowledge:
- Understanding of what reference-counted memory management is.
- Familiarity with the “ref/unref” pair, as opposed to only being exposed to something like the OpenStep “retain/release” (or even the COM/XPCOM “AddRef/Release”) terminology
- At least passing knowledge of what a GObject is
Now, for code that makes heavy use of reference counting, I think presupposing #1 is not unreasonable. In this case, it doesn’t matter: the comment as presented will not help you if you don’t know what reference counting is.
Points #2 and #3 depend on your goals and potential audience. If you think that a decent number of readers may not be familiar with the “ref/unref” terminology, “take a reference” is probably enough to generate an “oh, duh!” moment in the reader’s head. As for #3, unless you intend your code to be able to act as a sort of GObject tutorial, that is, something that people aspiring to learn GObject programming might want to read, I think the comment there does not serve people unfamiliar with GObject. Regardless, most GObject-using code will probably be pretty confusing to someone who doesn’t know GObject, so whether or not you should comment g_object_ref() is going to be the least of your worries.
Now, I’m not going to claim that my code commenting is perfect… far from it. I could certainly stand to sprinkle comments a bit more liberally throughout my code. I tend to only comment public API (and then just a description of what the function does, not how it does it), and code fragments that are really nontrivial[1] and potentially hard to understand.
But there has to be a happy medium somewhere. While too-infrequent commenting can certainly make code harder to understand, I’d argue that too-frequent commenting is worse. It’s sorta like “the boy who cried wolf” in the sense that comments draw my eyes to them as a way of saying, “pay attention! This bit here is important!” (or tricky, or whatever). Overuse of comments just makes me start skipping over all of them, useful or otherwise.
[1] It’s worth noting here that this point further reduces my volume of comments. I generally prefer clear code over neat hacks, even if the neat hack represents a reduction in lines of code or a moderate increase in performance. If I write a section of code and then look at it again and see that it looks too complex, I’ll usually try to immediately rewrite it to be simpler.
Xfce Stopwatch Plugin
I needed an excuse to try Mike's Vala bindings for Xfce, so I created a new little plugin for the panel, the xfce4-stopwatch-plugin.
In the original release announcement on July 28th, I wrote:
This is the first release of the stopwatch panel plugin, which you can use to time yourself on different tasks. It's stable and usable, but quite minimal still.
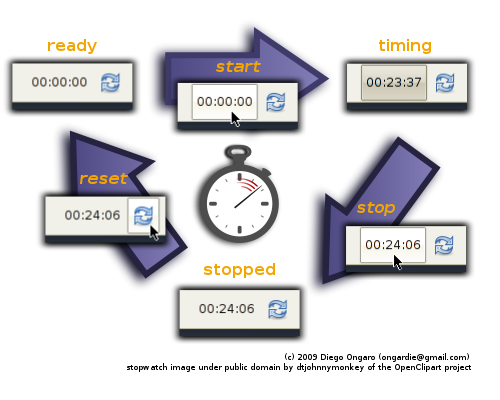
The functionality is best summarized with this image from the web site:
Vala
From their web site,
Vala is a new programming language that aims to bring modern programming language features to GNOME developers without imposing any additional runtime requirements and without using a different ABI compared to applications and libraries written in C.
Instead of having to write tons of boilerplate code to create new GObjects in C and for other common tasks in developing GTK-based applications, Vala builds these features into the language. The Vala code you write passes through the Vala compiler, which produces GObject-based C code. From there, GCC compiles that to a binary as usual. There is no runtime, so Vala-produced code can run as fast as hand-coded C.
Vala makes it easy to write fast, object-oriented code for GTK-based projects. With Mike's Xfce bindings for Vala, you gain access to Xfce's libraries from Vala, letting you write panel plugins or other Xfce projects in Vala. It's a cool idea and something I definitely wanted to try.
Developing the Stopwatch Plugin
In general, Vala is pretty easy to write if you've worked with GObject before. I did hit a few bugs while developing even this simple plugin, so it's evident that Vala and the Xfce bindings aren't mature yet:
-
I filed GNOME Bug 587150,
a bug in Vala's POSIX bindings for the
time_ttype. Vala treats it as a GObject instead of an integer, making it unusable to pass around your program in many ways. This bug hasn't seen any attention yet, but I've worked around it for Stopwatch by not usingtime_t.Update: Evan Nemerson fixed this one.
-
I patched
a small bug in Xfce's Vala bindings for the
XfceHVBox
widget. The Vala compiler was producing calls to
xfce_hv_box_new()instead ofxfce_hvbox_new(), which of course caused a problem when GCC tried to resolve the symbol. -
I also filed GNOME Bug 589930,
a bug in Vala's generated code for
sscanf. It always added an extra NULL argument at the end of the arguments list. Jürg Billeter fixed this one quickly with this commit, which made it into Vala 0.7.5.
Despite these hurdles, writing the Stopwatch plugin in Vala has been a pleasure. Admittedly the plugin doesn't do much, but the code is very short and straight-forward.
Stopwatch will probably see just one or two more releases before it's feature-complete. I'd also like to port the Places plugin to Vala at some point, but I'm waiting to see how volume management plays out once ThunarVFS is gone.
Xfce Stopwatch Plugin
I needed an excuse to try Mike's Vala bindings for Xfce, so I created a new little plugin for the panel, the xfce4-stopwatch-plugin.
In the original release announcement on July 28th, I wrote:
This is the first release of the stopwatch panel plugin, which you can use to time yourself on different tasks. It's stable and usable, but quite minimal still.
The functionality is best summarized with this image from the web site:

Vala
From their web site,
Vala is a new programming language that aims to bring modern programming language features to GNOME developers without imposing any additional runtime requirements and without using a different ABI compared to applications and libraries written in C.
Instead of having to write tons of boilerplate code to create new GObjects in C and for other common tasks in developing GTK-based applications, Vala builds these features into the language. The Vala code you write passes through the Vala compiler, which produces GObject-based C code. From there, GCC compiles that to a binary as usual. There is no runtime, so Vala-produced code can run as fast as hand-coded C.
Vala makes it easy to write fast, object-oriented code for GTK-based projects. With Mike's Xfce bindings for Vala, you gain access to Xfce's libraries from Vala, letting you write panel plugins or other Xfce projects in Vala. It's a cool idea and something I definitely wanted to try.
Developing the Stopwatch Plugin
In general, Vala is pretty easy to write if you've worked with GObject before. I did hit a few bugs while developing even this simple plugin, so it's evident that Vala and the Xfce bindings aren't mature yet:
-
I filed GNOME Bug 587150,
a bug in Vala's POSIX bindings for the
time_ttype. Vala treats it as a GObject instead of an integer, making it unusable to pass around your program in many ways. This bug hasn't seen any attention yet, but I've worked around it for Stopwatch by not usingtime_t.Update: Evan Nemerson fixed this one.
-
I patched
a small bug in Xfce's Vala bindings for the
XfceHVBox
widget. The Vala compiler was producing calls to
xfce_hv_box_new()instead ofxfce_hvbox_new(), which of course caused a problem when GCC tried to resolve the symbol. -
I also filed GNOME Bug 589930,
a bug in Vala's generated code for
sscanf. It always added an extra NULL argument at the end of the arguments list. Jürg Billeter fixed this one quickly with this commit, which made it into Vala 0.7.5.
Despite these hurdles, writing the Stopwatch plugin in Vala has been a pleasure. Admittedly the plugin doesn't do much, but the code is very short and straight-forward.
Stopwatch will probably see just one or two more releases before it's feature-complete. I'd also like to port the Places plugin to Vala at some point, but I'm waiting to see how volume management plays out once ThunarVFS is gone.
Code Comments
I’m a bit of a minimalist when it comes to commenting my code. This is probably in some ways a bad thing; code that is completely obvious to me in its function may be difficult to understand for others, and I’m often not so great at realizing this on the first pass. So that leads [...]The new Xfce release manager for users and packagers
I deleted the last post about the release manager because due to the high number of changes I made it was soon out of date. So let's get back to the topic again. I'll split it up into two posts: this one which is for users and packagers mostly, and another one directed to developers or, more precisely, maintainers.
Let's start with a simple question (with a long answer): what am I talking about and what is this release manager anyway?
First, a bit of background. At Xfce, we are currently working on improving our infrastructure. We are about to switch to git and along with that, our repository layout will change. Xfce and goodie repositories will no longer be found in separate locations. We thought it would be nice to implement the same layout in other places as well, like Bugzilla and our download archive.
Nick went ahead and enabled so-called bugzilla classifications and used those to resemble the repository layout on bugzilla.xfce.org.
That still left us with separate download archives for core Xfce, goodies and other stuff. For goodies, we had a very simple release manager web application written in PHP that uploaded tarballs to http://goodies.xfce.org/releases/ and was able to send release announcements to mailing lists. The design however was very limited. For Xfce releases we had nothing like that. Uploading and copying tarballs around manually for each release was what we had to do.
And this is where the new all-in-one release manager comes into play. It's called Moka, it is written in Ruby using Sinatra, ERB and JSON and the source code can be found here.
For you as a user or packager, it does two things:
- it uploads all (core and goodies) tarballs to http://archive.xfce.org which uses the same layout as our future git repositories and bugzilla
- it pushes release announcements out to mailinglists, Atom feeds, identi.ca and Twitter.
Download archive
The layout is described in the archive reorganization section of this mail. It contains releases of all projects, be they goodies, core components or something else. Again, we use classifications like apps, libs, bindings or core to add semantics the archive layout.
All tarballs are accompanied by an MD5 and SHA1 checksum file. In the future, we're hoping to also support PGP signing of tarballs. So, for the 0.4.0 release of terminal, you'll get these three files:
- Terminal-0.4.0.tar.bz2
- Terminal-0.4.0.tar.bz2.md5
- Terminal-0.4.0.tar.bz2.sha1
If you download one of the checksum files along with the tarball you can verify the download went fine with md5sum -c Terminal-0.4.0.tar.bz2.md5 or sha1sum -c Terminal-0.4.0.tar.bz2.sha1.
Announcements
Release announcements are sent to different mailinglists (almost always to xfce@xfce.org, so you're on the safe side subscribing to that one), identi.ca/xfce and twitter.com/xfceofficial.
The status updates on identi.ca/xfce and twitter.com/xfceofficial use the following format:
terminal 0.4.0 released! http://releases.xfce.org/feeds/project/terminal !Xfce
Atom feeds for all projects are available on http://releases.xfce.org/feeds/project/. There also is a dedicated feed for bundle releases of Xfce core components available on http://releases.xfce.org/feeds/collection/xfce. These feeds provide more information about the releases than the posts on identi.ca or Twitter do. There's no central feed for all releases yet, but you can as well subscribe to the feeds offered to you by identi.ca or Twitter.
Mailinglist announcements and feed posts use the same format. Here's a good example for a project release announcement:
xfce4-power-manager 0.8.3 is now available for download from http://archive.xfce.org/src/apps/xfce4-power-manager/0.8/xfce4-power-manager-0.8.3.tar.bz2 http://archive.xfce.org/src/apps/xfce4-power-manager/0.8/xfce4-power-manager-0.8.3.tar.bz2.md5 http://archive.xfce.org/src/apps/xfce4-power-manager/0.8/xfce4-power-manager-0.8.3.tar.bz2.sha1 SHA1 checksum: 2d531b9fc2afec3cff034e1acfc331051d8bf47a MD5 checksum: 0db6b6f5b13c8b0829c6a07b7dfdc980 What is xfce4-power-manager? ============================ This software is a power manager for the Xfce desktop, Xfce power manager manages the power sources on the computer and the devices that can be controlled to reduce their power consumption (such as LCD brightness level, monitor sleep, CPU frequency scaling). In addition, xfce4-power-manager provides a set of freedesktop-compliant DBus interfaces to inform other applications about current power level so that they can adjust their power consumption, and it provides the inhibit interface which allows applications to prevent automatic sleep actions via the power manager; as an example, the operating system’s package manager should make use of this interface while it is performing update operations. Website: http://goodies.xfce.org/projects/applications/xfce4-power-manager Release notes for 0.8.3 ======================= - Provides more standard org.fd.PowerManagement DBus methods and signal (bug #5569). - Make it possible to compile without network manager support. - Add never show icon to the system tray configuration (bug #5613). - Fix a typo that prevents from getting the correct critical configuration (bug #5619). - Use Gtk as a popup indicator to show the brightness level as the cairo seems to be problematic on some hardware. (bug #5544 #5632). - Better alignement in the interface file, worked by Josef Havran.
This is what the new release manager does for you. I think or rather hope that it provides an efficient way to to keep you posted about what's going on. And hopefully, all of you enjoy our efforts to unify our infrastructure and by that make things more transparent. As always, if you have any ideas for improvements, let us know!